

今年はクラウドが普及した1年だった
2009年もあとわずか、ということで、今年一年を振り返ってみたい。まずは年初に書いた「クラウド予想2009」についてから。
このなかでいえば、「クラウドを利用したWebサービス」は思ったほど出なかった。「Google Appsの一人勝ちだが一般的には広がらない」は、4月にGAE/Jが登場してからは圧倒的だったと思う。(まあ、まだ開発者中心ではあるが)
予想外だったのは、事例が出てくるのが非常に早かったこと。クラウドが流行るのはまだ先の話で、事例は当分出ないだろうと思っていたので、正直、そのスピード感には驚かされた。私自身、最初にクラウドに衝撃を受けたのが2008年の5月頃(※)だったので、それからまだ2年も経っていないことを考えると、本当にもの凄い広がり方であった。どれくらい凄かったか、以下の事例を見ていただくとよくわかるだろう。
(※ 私はこの記事を見て、Reflex iTextをクラウドに載せようと決心した。また、そのことを「究極のWebサービス。やられた感いっぱい ><。」 という記事に書いた。そして、公にクラウドという言葉を使い出したのが、「バーチャルテクノロジーは第二ステージへ」の記事を書いた同年8月頃だ。でもこの頃はまだ世間で通用する言葉でなかったのをよく覚えている。)
多くのクラウド事例が登場した
クラウド事例の代名詞的になった「エコポイントシステム」は、安く早く作れることを実証した事例となった。また、100万PVをこなすmixiアプリモバイルコンテンツやモバツイッターは、スケーラビリティの凄さを見せつけた。海外では、BuddyPoke!やPixverseなどが出てきた。
他のGoogle App Engineの事例では、プログラム申込予約システムや会員管理、タスクマネージメントシステムや、ECまでもある。
GAE以外の事例では、AzureのWebアルバムサービスなんてのがある。
Google App Engineには、セキュリティに懸念があり、また、月平均に1~2回の定期メンテナンスがあって可用性も低い。過去に大きなトラブル「Google App Engineにデータストアの障害発生。復帰まで約6時間、原因は現在も不明」も引き起こしている。実運用に耐えうる可用性や信頼性を確保するにはまだまだ時間がかかりそうという印象をもっている。なので、実際の受注システムや会員管理などは時期尚早と思われたが、意外と多くの事例が出てきている印象がある。
あと面白いのが、R-SPICE。これは、Salesforce.comとGAEを組み合わせたアプリケーション。この事例のように、ChartAPIや他のGDataAPIをWebサービスをマッシュアップして利用するパターンが今後増えてくると思われる。WebサービスはAtomやRESTといった単なるAPIとして使うことを前提とされており、汎用性が高く、クラウドのスケーラビリティ、使いたいときに必要なだけ使えるというユーティリティ性をいかんなく発揮できるのが特長だ。GAEのWebサービス事例としては、画像変換サービス や、弊社のReflex iTextサービスなどがある。GDataAPIのなかでは、個人的には、PicasaやGoogle Analitics APIに大きな可能性を感じている。欲を言えば、大量のテキストを格納できるストレージサービスと全文検索サービスを今後提供してほしいところ。全文検索はPicasaの説明文に文字を格納することで一応可能だが、最大1024文字であることと、写真付きでなければならないのが痛い。また、大量に保存する場合、GMAIL/PICASA並の料金にまで下げて欲しいところである。非常に安く提供できるという点はクラウドにとって最も重要なところである。
これらクラウドサービスを提供し始めている企業は、大手ITベンダーというよりはむしろ中小ソフトウェア開発会社の方が多いという傾向があるように思う。弊社もそうだが、前述した写真サービス変換は有限会社アルコルさん。先日サービスされた、雨の日メールのplusvisonさんなどが事例を発表している。数人規模の有限会社でもサービスを提供できる点がGAEの凄いところで、それを可能にしているのがPublicクラウドのインフラ技術。私たちが実際に利用しているデータセンターはGoogleであり、胸を張って大手と張り合えるだけのインフラがあるといえるのが強みである。
不景気だからこそクラウド
昨年の夏、景気が悪くなるからこそクラウドという記事を書いた。9・15に起きる、リーマンショックの約1ヶ月前のことで、まだ景気は悪くなっていなかった時期のことである。今は不景気の話でもちきりだが、当時は周りに話しても( ゚Д゚)ハァ? みたいな感じで、特に興味をもたれなかったのを覚えている。だが正直、言った本人もこれほど悪くなるとは思っていなかったので、全然説得力がなかったかなとも思う。
いざ大不況になると、大変な変化が起きていることが、実感として感じざるを得ないようになってくる。IT業界でも単価の下落だけにとどまらず、案件そのものが無いという現実を経験した。かねてから下請けに未来は無いとは思っていて、クラウドビジネスへの転換は必然と考えてはいたが、これほど早い時期に不況が訪れて、急転換を迫られるなんて思いもしなかった。
だが、お客様企業においても、不況に対応するために、大きな変化が要求されているのも事実である。
いくつか相談をいただいたなかで多いのはコスト削減が一番であった。企業にとってITコスト削減要求が大きくなってきている現状をみると、部分的な利用に限っては、意外と早い時期にクラウド利用が進むのではないかとも思えてきた。
というのは、削減目標が1/10とか、企業の管理者の間で飛び交っている話は、もはや、これまでのアーキテクチャーではとても成し遂げられないような無茶なレベルで要求されており、それを踏まえたうえで、私たちへの依頼についても、「常識にとらわれない提案をしてほしい」と、案にクラウドを期待するものも多くなってきているのもあった。これは、昨今のクラウドブームが背景にあるのも大きい。しかし、お客様自身に、現状のコストを抜本的に抑えられないアーキテクチャーのままではいけないという認識が大きくなっているのも事実であった。おそらく、この大不況がなければ、ここまで切羽詰った状態にならなかったのではないかと思う。これが原動力となって、エンタープライズへの移行シナリオにあるように、段階を得ながらクラウドに移行していく企業も出てくるかもしれない。さらには、ビジネスを変える8つの方法にあるように、ビジネスを変革できる付加価値も出てくるとなれば、当然、期待も大きくなっていくだろう。そう考えていくと、大不況は私たちにとって追い風であり、苦しいけれども、ITイノベーションを発展させていくうえで、必要な過程であると納得せざるを得ない。
しかし、一方で「自治体クラウド」といったような、ITイノベーションに逆行する酷いものもある。3割~4割カットなんてお手盛りミエミエの自治体クラウドは、ビジネス的にも技術的にもクラウドとは全く関係ない世界であり、霞ヶ関と大手ITベンダーによる「雲の上」の茶番劇にすぎない。これは税金を使った大手ITベンダーの延命策にすぎず、ITイノベーション発展には何の寄与もしない。こんなことやっていると、せっかくお客様に芽生えたクラウド化への意識や原動力を削ぐことにもなりかねない。そして、税金が尽きたころには日本はクラウド技術で取り残され、世界に無残な姿を晒すことになるだろう。ああ、いっそのこと予算なんて付かなきゃいいのにとさえ思う。
クラウドの定義とエンタープライズへの移行シナリオ
クラウドが普及してバズワード化してくるなかでミソクソになる、というのは年初の私の予想通りであった(弱者連合とスケーラビリティ、最近では、CBoCやプライベートクラウド スタートアップキットなんてのも出てきた)
ここでひとまず、モヤモヤしているクラウドの定義について、あらためて過去の記事を列挙することで、整理したいと思う。
クラウドは言われだした当時から定義がモヤモヤしていたことは事実で、クラウドを15の否定で表現なんてのがあった。
私が考えるクラウドとは、クラウドの本質と動向に書いたとおり、Scale outするシステムのことであり、抽象的に定義されたデータベースサービスへのアクセス手段を提供するものである。これは、昨年10月に書いたものなのでちょっと古いと感じるかもしれないが、今のところ私の定義は変わっていない。付け加えていうなら、クラウドは、Webサービスによる疎結合アーキテクチャーを基本としていることが特徴である。(ちなみに、弊社のReflexは、 RESTfulな新3層アーキテクチャ)にあるように、疎結合を基本に考えているので、クラウドに馴染みやすいという特徴をもつ。)
大きく分けて、PublicクラウドとPrivateクラウドがあるが、どちらもScale outするという基本的なアーキテクチャーは同じである。Privateクラウドは、エンタープライズシステムのクラウド移行にあるように、コモディティサーバとオープンソースを基本とする分散KVSの基幹システムへの適用である。下図の価格シミュレーションは単純にHW価格だけを比較したものだが、1/4から1/3のコストダウンを図れる計算になる。

また、下図のサーバインフラの変遷にあるように、突き詰めれば複数のCPUが疎結合で連携するような処理を、1チップのなかで実現することを可能にする。Scale outアーキテクチャーが1Chipにまで応用可能であるということは、クラウドがイノベーションである証拠といえよう。(参考:流行りのクラウドは48コア・プロセッサで?)

エンタープライズへの移行シナリオは、M先生にいわせると楽観的である。これに関連する話で、タイムリーに以下の投稿がMLにあった。
アマゾンのOです。
初めて投稿致します。
技術系の話題でなくて恐縮なのですが。。。
今週1週間、本社(シアトル)のほうに来ておりまして、いろいろ
情報を仕入れているのですが、個人的に驚いたのがこちらでは
大手企業でのクラウド利用状況が思いのほか進んでいることです。
本社営業チームの2010年向けの案件レビューに参加する機会が
あったのですが、大手どころに毎月かなりの金額でご利用
いただいていることが分かり、またその規模も急速に伸び
ているのがわかり、ちょっと驚きました。
で、Enterpriseでのクラウドビジネスは(もちろんスポット
利用も広告、メディア業界には多いのですが)保守ビジネスと
同じようなストックビジネスなので、毎年売上が積み上がって
いく感じなんですね。
頭では理解していたつもりなのですが、実際に営業報告のグラフ
等で見ると、改めてこのビジネスの伸び、将来性がわかった気
がしました。
こうしたトレンドは近いうちに日本でも見られるようになると
思うとなんだか楽しみな気がしてきました。
皆様にもこのワクワク感をお知らせしたく、シアトルからメール
している次第です。
機会があれば、こうしたビジネスでの広がりについても
研究会でお話ができればと思います。
それでは。
Publicクラウドの特徴と覇権争い
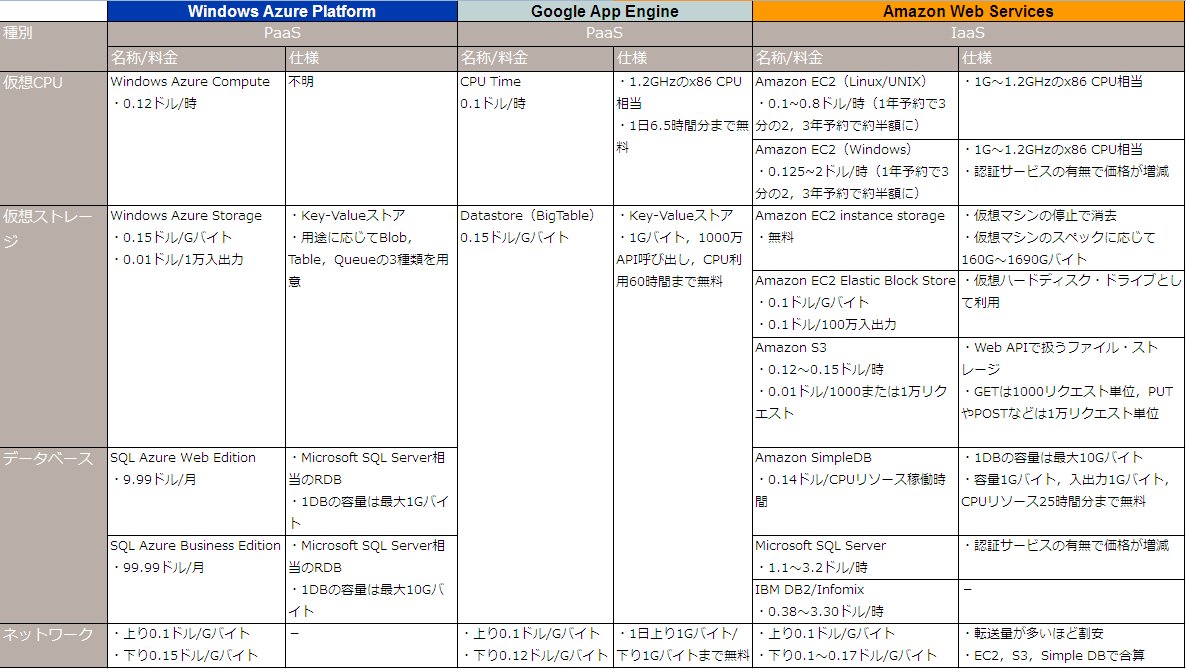
一方、Publicクラウドは、 格安ストレージを利用するのなかで説明した図のように、べらぼうに安いのが特長である。運用コストも含めて、とにかく安くできるというのがウリで、逆にそれ以外のメリットはあまりないかもしれない。例えば、可用性は低くなり、セキュリティやベンダーロックインといったリスクは大きくなる。Scale Outアーキテクチャーを重視するなら、RDBをクラウドに載せるべきかという記事で書いたように、RDBというアーキテクチャーを諦めなければならないケースもある。柔軟に考えているAzureはRDBを採用することも可能だがこの場合はスケールしない。
繰り返しになるがPublicクラウドの最大のメリットは低いコストである。GoogleやAmazonがこれを可能にしているのは、大規模なデータセンタをもっているスケールメリットや、コンテナ型で電気代などを含む徹底した管理コストの削減を図っていることもあるが、本業で使っている余剰インフラを提供している面も大きいのではないかと思う。(Googleは検索エンジン、AmazonはEC) そう考えると、弱者連合は太刀打ちできないだろう。
特に、Googleの強さが際立つのであるが、ChromeOSと世界の対立軸で述べたように、IBM vs Google というよりは、MS vs Googleといった色合いが濃いと思う。企業向けという意味ではAzure(※)もかなり善戦しそうである。
(※)大規模コンテナ型データセンターを構築している。参考 日経BPの中田さんによるAzure IT PACの写真
ただ現時点でのGoogleは、失敗しないことがよいことかでも述べたように、イノベーションリーダであることは間違いないだろう。

Publicクラウドのpros cons
パブリッククラウドとビジネスモデルで述べたように、Publicクラウドはセキュリティや信頼性がトレードオフになる分、安くなければ意味がない。
また、Scaleするかどうか、それが問題である。
Publicクラウドにおいては、セキュリティは最後の難問題であり、クラウドに企業情報や個人情報に近い情報を蓄積するにはセキュリティ面で不安が残るのは当然である。そもそも、クラウドにおいても企業内同様のレベルで守られて当然と考えるには無理がある。それは、内部規定で関係各所のPマークの取得やIPS構成の報告が定められている場合など、企業内データを外に出して保管すること自体、セキュリティポリシーとして禁じられているからだ。これを回避するには規定そのものを改正する必要がある。
前述したが、現時点におけるPublicクラウドの可用性はまだ低いといわざるを得ない。オンスケジュールとはいえ、平均2回/月の停止は回数が多いと感じる。
また、技術的に冒険的要素が強く、コスト面のメリットを勘案しても慎重にならざるを得ないと考えているお客様も多いだろう。特に、開発や運用における技術的ハードルが上がる点で不安が大きいと感じているようである。ただ、これに関しては、事例が増えて開発運用ノウハウが蓄積されていくことで解消されていくだろうと楽観している。
クラウドには向き不向きがあり、業務アプリによってはむしろ自前でやった方がいいのも多い。クラウドでやるか、自前でやるかの判断は、最終的にはリスクを取られるお客様の判断になるという点は強調すべきである。最近ではクラウドのメリットばかり強調され、これらデメリットについて深く考えることは少ないのだが、むしろお客様にはデメリットを正直に説明することで、正しく理解していただくことが重要である。
前述した事例のように、それでもクラウドに向いている業務アプリは多くある。それらをうまく拾っていきながら私たちはビジネスを広げていければいいと思う。
クラウドをどうやってビジネスにしていくか
エンタープライズの移行シナリオでは利用する企業の視点で述べたが、最後に、私たちクラウドサービスを提供する側のビジネスについて述べたいと思う。
クラウドで商売をやるには、もっと根本的にやり方を変えていかなければならないと感じている。従来は、偽装請負のススメで説明されているような発想が基本だったが、ビジネスモデルが変わるのだから、単にGAEで請負をやるという考え方ではなく、パッケージ販売のような小売業に近いビジネスへの転換が必要だと思う。
以前、Publicクラウドはサブスクリプションモデルがいいという記事で、GAEやAmazonEC2などのpublicクラウドは、大企業から請負で開発するというビジネスモデルより、コンシューマをターゲットに小売的な商売を行って、使ってもらってナンボといった感じのビジネスモデル方が合うような気がしていると述べた。たぶん、これぐらいの大きな発想の転換は必要で、GAEを使ったアプリの開発を請負ってもいいけれど、作ったものを収めるというよりは、利用してもらって料金を徴収するといったモデルに少しでも近づけていくのがいいのではないか。Publicクラウドというすばらしい環境があるのだから、やってやれないことはない。
ポイントは、顧客の欲しい“最終製品” を迅速に提供していくこと。
5年後のIT市場でいったように、「ソリューション提供とかシステム構築などの業界用語は死語になる。顧客の欲しい“最終製品” がクラウドから出荷されるからだ」という話には非常に説得力があると思う。
ただ、“最終製品”を売っていくには、相当のクオリティが求められるということも付け加えておく。小売に共通していえることは、クオリティの高いものでなければ、生き抜いていけないということ。クラウドに言い換えるとパフォーマンスやスケーラビリティ、あるいは、安くて短納期といった要素が重要になってくるだろう。Sales Forceの事例は、そのあたりのアピールが非常にうまいと感じている。要はカスタム化することで、様々な要求に迅速に対応できることをいっているのだと思うが、同じことをGAEでもやれることを示していけばよい。
高いクオリティのものを安く売る秘訣については、小売の盟主ユニクロに学ぶことも多いと思う。例えば、UNIQLOCKのようなBlogパーツは、なかなか思いつかない。
私自身、暮らしのデザインという小売を経験して、それが企業相手の商売とは全く異なるものだということだけは少しわかったつもりでいる。







































{kind=link}