

10人くらいだったら完全非公開にしようと思ったんだけど、30人くらい来てくれたので公開することにしました。 UST録画はこちら
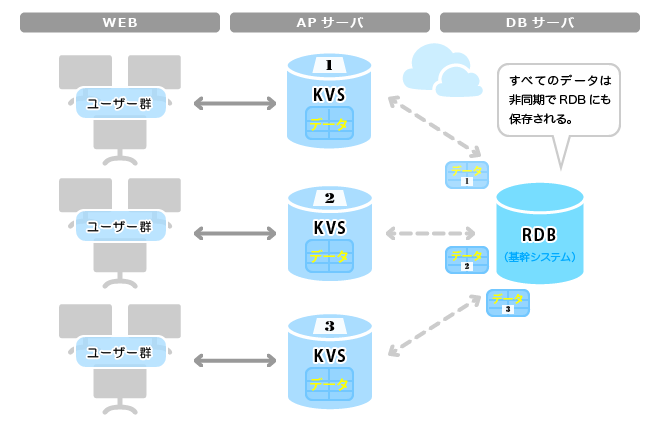
BDBの代わりにRDBのインスタンスを複数配置するんじゃだめなの?というのはよく聞かれる質問だけど、昨日も当然のように質問された。
いつもうまく答えられなくて歯がゆいけど、それは、O/Rマッパーも必要なくなって、RDBを導入管理する必要がないから。だけど、そこはやっぱり伝わんなかったかな~。
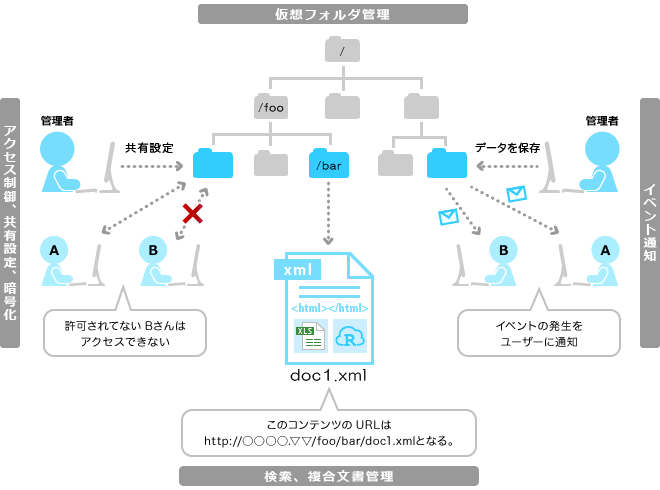
O/Rマッパー無くしてソフトスキーマで
開発の4割がマッピングといわれ、 それに、テーブル設計、正規化、SQL、チューニングなど、 ほとんどがデータベースまわり。要は、これを全否定したいわけ。 直接オブジェクトを格納するわけだからO/Rマッパは不要になる。
昔、EUC(Enduser computing)とか言ってたっけ。
Lotus Notesでアプリ開発したことある人ならわかると思うけど、 RDB不要な感じでスキーマを自由に作れる開発環境は、(流行ってるかどうかは別として)、珍しいものでも何でもなく、一度経験するとその高い生産性に慣れてしまって、もう元には戻れなくなる。RDBは大変な負荷だったんだと気づく。
Lotus Notesでアプリ開発したことある人ならわかると思うけど、 RDB不要な感じでスキーマを自由に作れる開発環境は、(流行ってるかどうかは別として)、珍しいものでも何でもなく、一度経験するとその高い生産性に慣れてしまって、もう元には戻れなくなる。RDBは大変な負荷だったんだと気づく。
最近では Google App Engineや最近ではBaaSといったWebサービスもソフトスキーマで、アプリケーション内で自由に項目を設定できる。
ACIDのDどうすんの?
だって、APサーバごとにRDB導入するわけにはいかないでしょう? だから普通はDBサーバのインスタンスを分けようという話になる。でもそれだけでスケールするんだったら苦労なんてしないわけ。結局、AP側にキャッシュを入れようという話になって、今だとRedisが使われるじゃないですか。で、永続化すればI/Oが詰まるので、どう溜めるかをよく考えないといけなくなる。つまり、ACIDのDをどうするか。トランザクションリカバリーとか、むしろ障害対策を頑張って作る必要があるんだけど、皆さんどんなふうに解決しているんだろうね。Append only fileで頑張ってる? まあ、2.4で非推奨になったVirtual Memoryを自力で作るぐらいの覚悟があれば大丈夫なんだろうけど。
一方のBDBは、DBMSと同等のACIDがあるので、トランザクションログからのリカバリもDBMSと同じようにできる。単純なログファイルに書かれるだけだから、スケールアウトして複数ノードになったとしても運用はチョー楽チンだ。
BDBは、他のKVSと比較して特別に速いもんじゃないし、高機能というわけじゃない。
でも、APのプロセスで動作する一つのjarがあって、処理自体は当然メモリー内で実行されるからキャッシュ技術と同等のパフォーマンスぐらいは出せる。また、APサーバ内だけで完結するからDBサーバは実質的になくても動作する。この辺りが魅力かな。
ついでにスクリプト言語も(ry
もうそろそろ、サーバはデータを返すだけでよくないか?
twitterの例はあるとは思うけど、レンダリングはクライアントでもう十分だろ?
こんな感じで、乱筆すみませんでした。
みなさん、よいお年を。






























{kind=link}