

キャッシュ技術の限界
DBMSのボトルネック解消手段としてよく使われるのがキャッシュ技術である。キャッシュ技術には、OSSのMemcachedや、JavaEE7のJCache、Oracle Coherence, WebSphere eXtreme Scaleといった商用製品などがあり、メモリキャッシュをAPサーバに置くことでDBのボトルネックを軽減させることができる。 なかには、トランザクションをサポートしているのもあり、読込だけでなく書込においても効果を発揮して、DBMSの負荷は大きく軽減できるようになる。
たしかに、キャッシュ技術を使うことで高速化(低レイテンシ)を実現できるが、一方で実は改善できるのは高速化した分だけ、という見方もある。頻繁に使うマスタ参照や数千tps以上といった大規模リクエストの緩衝機能として効果は見込めるものの、実際にキャッシュ読込のために最低1回はDBにアクセスしなければならず、永続化の問題(揮発性のためデータがロスする)やDBとの整合性の問題がある。また大規模なメモリが必要になるとコスト面でもメリットは少なくなる。つまり、キャッシュはあくまでキャッシュであり、リニアに無限にスケール拡張ができる技術とはいえないということである。
2008年当時、企業内クラウドは、最初は大手ベンダーによるキャッシュ目的で導入され、最後はアーキテクチャ変更をもたらす(参照)といったような楽観的な予測もあったが、いろいろ経験するにつれ、もう少し踏み込んだ発想をしないとブレークスルーはしないと私は考えるようになった。
主従逆転の発想
前述のように、キャッシュメモリをどんなに積んだって最後はRDBがボトルネックになるのは必然であり、これを解決するにはアーキテクチャー変更が伴うわけだが、だからといってRDBを否定してKVSで全部代用できるとは思えない。企業にはRDBのために特別に用意された耐久性に優れた高性能サーバが厳然と存在しており、今後もRDBがシステムの中心として君臨し続けることは間違いないからだ。Webの3-Tierアーキテクチャーも基本的には変わらないだろう。
しかし、オンライントランザクション処理に限っていうと、トランザクション処理とデータストアの分離ができれば、スケールしないRDBを必ずしも使う必要はなくなる。つまり、単にRDBをデータの格納場所として使い、オンライン処理の基盤としては別のものを使うことで、RDBがボトルネックになるのを防ごうという発想である。
具体的には、キャッシュの発想をもう少し進化させたような感じで、APのKVS内だけでトランザクション実行を完結させ、RDBとはEventual に同期するような仕組みとすることで、RDBに負荷が集中することを防ぐ。参照系(マスタ、トランザクションのREAD)はRDBへアクセスしなくてもKVS内で実行できるようにする。要はKVSだけでアプリの実行(READ,WRITE)ができるようにすること。これを実現するには、KVSでアプリのデータ操作をすべて賄える必要があり、ACIDトランザクション処理を確実に実行できかつ永続性を備えることは必須となる。
1.マスタ等をKVSに配置する。参照(READ)はKVS内で実行しRDBに参照しにいかない。
2. トランザクションの参照(READ)はKVS内で実行する。RDBに参照しにいかない。
3. トランザクションの更新(POST,PUT,DELETE)をKVS内で実行して保存する。非同期に更新結果をRDBに送信する。
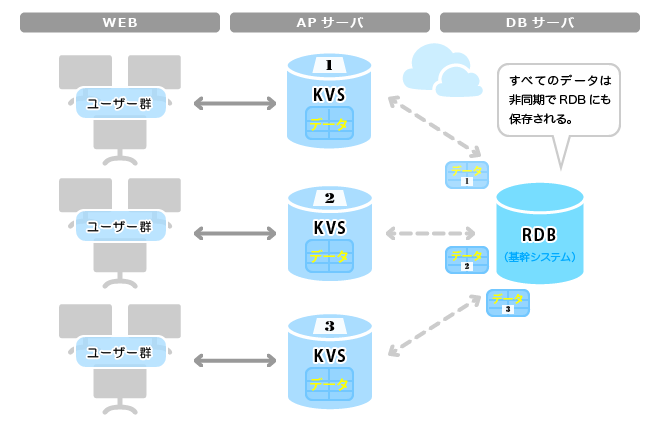
この図を見てもわかる通り、実はWeb-AP-DBの3 Tierのアーキテクチャーは崩していない。ただAPサーバ内にKVSというトランザクション処理基盤を導入しているだけである。(3Tierというだけで企業にとってはずいぶん敷居の低いものに見える)
だがこうすると今度はRDBとの整合性が問題になる。RDBはEventualに更新されるためタイムラグが発生する。例えば、実際にはKVSで既に注文を受け付けているのに、RDBではまだ受け付けられてない状態になっているかもしれない。
実はここが最も重要なポイントで、整合性※などが問題ないように、うまく設計する必要がある。(※ 整合性と一貫性はどちらもConsistencyの意味で使われるが、私は、オンライン処理などの同期処理において矛盾の無いことを保証する場合に一貫性といい、非同期処理においてデータに矛盾の無いことを保証する場合に整合性といっている。この使い分けが正しいかどうかはわからない。)
1点目は、遅延を許容すること
正のデータは常にKVS上にありリアルタイムに更新されているが、RDBは若干遅れて更新されることを前提に考える。オンラインの範疇はKVSまでとし、RDBから以降はバッチ処理と割り切ることができるかどうか。ここはeventually consistencyというと語弊があるので、単なる非同期更新と考えてもらえればと思う。
2点目は、整合性を保証するプロトコルとすること
データはレコード単位に(システム全体で)ユニークかつバージョン(リビジョン)管理する。また同じデータが複数ノードに散在している可能性があり、RDBを更新する際は何回更新されても同じ結果になるようにする(べき等性)
さらに、あるノード上のデータがRDB更新前にダウンした際にも、KVSのログ等からコミット分を抽出してRDBに反映できること。(トランザクションリカバリー)
ReflexWorksでは、データはユニークなIDとバージョン(リビジョン)番号で管理されており、整合性は常に保たれる。もともとスマホやChromeのオフラインアプリなどでネットワーク分断があっても整合性を保つために導入した概念だが、APとDB間を含むシステム全体で整合性を保証することにも利用している。






{kind=link}
0 件のコメント:
コメントを投稿