

「Web API Advent Calendar 2014 の5日目の記事です。」
最近、Isomorphicという言葉をよく聞く。
Isomorphicとは、サーバーとクライアントのコードを同時に記述するパラダイムのことだ。
つまり、フロントエンド・バックエンドを曖昧にするようなアーキテクチャである。
私は、IsomorphicはWebのアーキテクチャーに合っていないと思っていて、やはりAPIファーストで設計し、フロントエンド・バックエンドをきちんと分けるべきだと考えている。
この点について詳しく述べたいと思う。
Isomorphicな開発環境が求められる背景
Isomorphicな開発環境が求められる理由としては、こちらのMeteorの記事が大変わかりやすい。(リアルタイムWebアプリケーションフレームワークMeteorについて)
- 普通のWebでは状態が画面遷移でリセットされてしまうことが辛い
- バリデーションをフロントエンド・バックエンドの両方で実装しなければならない
- フロントエンドだけのスキルでは不十分。バックエンドの実装が特に面倒くさい。
- フロントエンド・バックエンドを別々に勉強するのではなく、同時に作っていくイメージで開発したい
フロントエンドでも簡単に永続化されたオブジェクトにアクセスできるような仕組みのリアルタイムWeb開発フレームワークが欲しいということだと思う。Meteorであれば実現できるらしい。
例えば、meteorはフロントエンドでもバックエンドでもない、"Isomorphic" なフレームワークであり、WebSocket を利用しつつ pub/sub モデルで抽象化したような形で同期を取る。
Isomorphicなフレームワークの課題
2012年に登場して脚光を浴びたMeteorだが、それ以降は大きな広がりは見せていない。
Meteorは果たして失敗したのか。であるならその原因は何だったのか。
個人的に思いつくものを挙げてみる。
1. 信頼性の低いWeb環境を甘くみたこと
いつもいっていることだが、「分散システムでは信頼を失う」という真理に目を背けてはいけない。
リモートでは読込に時間がかかったり、更新に失敗したり、失敗したかのように見えて実は成功していたりということを考慮しないといけないはずなのに、ローカルと同様のシンプルな手続きで実行できるかのようにして本当に大丈夫なのか。
古くはJavaRMI、IIOP、RIAなど、誰もが挑戦して失敗を繰り返してきた歴史がある。これら死屍累々の歴史から学ぶべきことは多いように思うがなぜ生かされないのか。
2. 密結合になりがちなこと
ローカルにあるオブジェクトを更新するかのようにリモートのオブジェクトの同期を取ったり、逆にリモートのオブジェクトの更新があればローカルにも更新を伝達するような仕組みは、リアクティブかつ非同期に実行すればできそうに思える。(もちろん、正しく同期を取るにはデータのバージョニングまで行わないとでできないだろうが)
しかし、たとえ仕組みが出来たとしても、フロントエンドのオブジェクトが勝手に永続化されバックエンドとリアルタイムに同期していくというのは、シンプルであるがゆえに密結合へと誘導してしまう危険性もある。
Isomorphicな環境がフロントエンド・バックエンドの密結合をもたらしてしまった結果、パフォーマンスや拡張性などの様々な問題を生み出してしまうことになる。Meteorももれなく、そういった問題にぶつかったのではないかと想像する。
3.モノリシック(重厚長大)になりがちなこと
また、Isomorphicなアプリでは、モデルの操作含めフロントエンドにコードが集中していきバックエンドではほとんど何もしないということが多い。それはそれで一見良いようで、サーバで実行する方が効率的なものまで無理にクライアント側でやってしまうということが起りがちである。
実際にMeteorでは相当なモジュールをフロントエンドに作りこんでいるが、まともにプロダクションで利用できるレベルを維持していくのは大変だろうと推察する。
4.サーバサイドはどのみち意識して開発せざるを得ないこと
よくよく考えてみるとバックエンドを無視して作ることなんて実は不可能だということに気づく。
フロントエンド・バックエンドで同期するデータソースを実現し、また、バリデーションの定義を共通化したにしても、バックエンドでだけ実行すべき部分というのは必ず残るのだ。
例えば、IDなどのシーケンス番号の採番や、商品金額のマスターチェックなどは、整合性や不正が発生する可能性があるためフロントエンドだけでは実行できない。
サーバを意識しないのが無理なら、フロントエンド・バックエンドを区別無く隠蔽するのはむしろ開発を困難にしてしまうことにならないか。一見シンプルで作りやすそうで、エラー処理などによって複雑になってしまうのでは本末転倒である。
これについては、「node.jsで Isomorphic フレームワーク作ってみようとしたら超辛かった」を読むと困難さがよくわかる。
このように、Isomorphic化は苦労するわりには益が少ない。
開発生産性が劇的に向上するわけではないし、コードが奇麗にかけるとか自己満足の域を出ていないように思える。
Web系の人と組み込み系の人で意見がわかれるところかもしれないが、私はフロントエンド・バックエンドは明確にわけて記述する方がわかりやすいと思う。また、そもそも一人で開発すべきではないとも思っている。一人で作ろうとするから区別したくないと思うわけで、複数人であればそういう要求も出てこないのではなかろうか。
APIファーストとSPAはサーバサイドをスリム化させる
フロントエンド・バックエンドを分離してAPI主体で開発していく「APIファースト」と呼ばれる開発手法がある。
アプリ開発者はAPIのレスポンスだけを知っていればいいため、それぞれが独立して開発に集中でき、かつそれぞれをスケールさせることが容易になる。
最近、Micoservicesが注目されているが、API化はモノリシックなサーバサイドを分割してスリム化する効果が大きいことがわかっている。
弊社が請け負った実際のSPAアプリでの割合はクライアント6に対しサーバ1であった。
サーバサイドのスリム化を図りたい方はまずAPI化してSPA化するのがよいと思う。
API設計でCoC(設定より規約)が受け入れられるか
APIファーストのWebフレームワークでSynthというのがある。
これはフォルダをつくってや特定の方法に則った関数名をつけるだけで簡単にAPIが作れるもので、弊社のReflexWorksの考え方によく似ているのだが、「機能に影響するような新しい命名規則を覚えること」への批判もあって、今後どういう展開になっていくか興味をもって見ているところである。
実は、先日書いた記事でも似たようなことが指摘された。
サービスをそのままURLマッピングするのは筋がよくないという意見である。
URLにはそれが何をするものなのかや振る舞いが予想できるといった点が重要と考えています。静的コンテンツの場合はディレクトリにファイルを配置するのは自然なイメージだと思うが、サービスが絡んでくるとどのように振るまうかがわからないのでイメージするのが辛いということだった。これは一理あると思う。
d/{リソースID1}/・・/{リソースIDn}
的な仕様の場合、どのように振る舞うのか想像できません。
ReflexWorksではサーバサイドでJavaScriptを実行できる。そして、ディレクトリの構造をそのままURLにマッピングできる。例えば、POST /s/booking をサーバで受けると、/booking.jsを読んでdoPost()関数を実行する。
これは、Restfulな新3層アーキテクチャで示すようなAPI表現 entity = blogic(entity) の考え方に基づいている。やろうと思えばIsomorphicにできると思うが敢えてやらない。
機能に影響するような新しい命名規則を覚えることの批判に対して、直感的な命名規則CoC(設定より規約)というスタンスが果たして受け入れられるのか、また、振る舞いをイメージしずらいという意見にも十分に応えられるのかが課題だと思っている。
負の遺産化を避ける
規約のないサービスAPIがいかに酷いものであるかは言わずもがなだ。
昔のSOAP時代によく見られた「お勝手API」はREST全盛の時代の今でも散見される。
REST制約が効いているとはいえ残念なURIになっているサービスはまだまだ多い。
そういうAPIにはお近づきにはなりたくないと思うのは私だけではないだろう。
BaaSがイマイチ流行らないのは残念なURIに付き合うコード書きたくないからだと思う。
技術的負債になるとわかっているから皆近づかないのではないか。
ロックイン、膨らむ学習コスト、不具合があったときのリスク、拡張性の欠如等々の技術的負債を考えてしまうのだ。
とにかくAPIを汎用的にすることで将来の開発に負の資産を残さないことが重要である。
ReflexWorksやSynthが主張するCoCで命名規則という発想は負の遺産化を避けることになるかもしれないと思うのだがどうだろう?
2つの現実解
ここまで、Isomorphicについては密結合・モノリシック肥大化の懸念がある一方で、APIファーストについては命名規則の批判や振る舞い表現に課題があることを示してきたが、結局どのように設計していけばいいのかについて最後に述べてみようと思う。
つまるところ、フロントエンド・バックエンドを同じコードで実行できなくても同様の効果をもたらすようなものを考えていけばよく、とりわけバリデーションの共通化とキャッシュ利用の2点は効果的だと考えている。
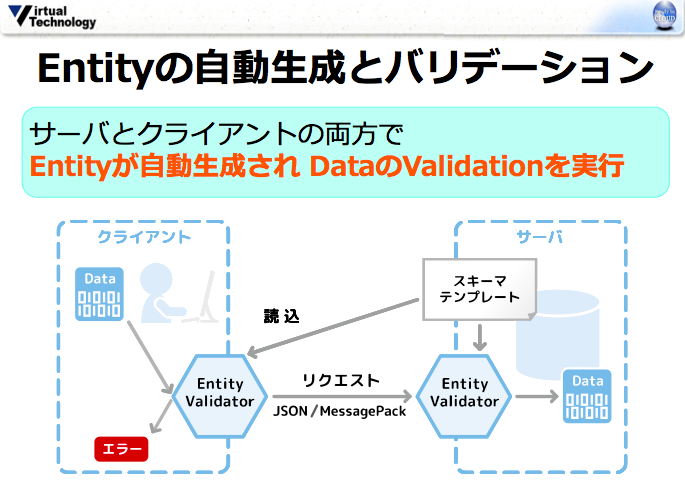
まず、バリデーションの一元化についてスキーマによる自動生成の仕組みを紹介したい。
これはReflexWorksでも採用している方法だが、共通のスキーマテンプレートからフロントエンド・バックエンドのバリデーションロジックを自動生成するというやり方である。
スキーマテンプレートについては、詳しくはこの記事を参照してもらいたいが、簡単にいうと項目名や型、正規表現のバリデーションルールなどを1項目につき1行で記述したものだ。
全く同じコードが生成されるわけではないが、正規表現などを使ったバリデーションはクライアントサイドとサーバで同じように動作させることができる。
詳しくは、12/10 のセミナーで説明するので、興味ある方はぜひご参加下さい。
「AngularJSとReflexWorksで始めるSPA開発 ~もうサーバー側で悩まなくて大丈夫~」
参加申し込み => compass
次に、キャッシュを利用した例であるが、firebaseでは以下のような機能がある。
publickeyより
Firebaseを利用することで、すべてのクライアントとバックエンドのデータがリアルタイムに同期する、いわゆるリアクティブプログラミングが実現するわけです。
しかもあるデバイスがオフライン状態になっても、そのデバイスでのデータ同期が止まるだけでアプリケーションの動作に影響はありません。オンライン状態になった時点でバックエンドとのデータ同期が自動的に行われます。
このようにFirebaseでは、アプリケーション開発者がデータ同期の方法やネットワークのオンライン、オフラインの状態を気にすることなく、Webアプリケーションやモバイルアプリケーションの開発を可能にします。
実はReflexWorksのAndroidAPIも同様の機能を実装している。オフラインであってもリクエストを受け付けるし、裏で勝ってにバックエンドと同期を取ってくれる。
ただし、フロントエンドにあるデータはあくまでキャッシュであり、バックエンドにあるものとは時間差があることには注意を払う必要がある。また、バックエンドと同じ量のデータをフロントエンドに持つことも現実的ではないため基本的にサブセットになる。
要はこれで十分ではないかということがいいたい。
Isomorphicであることは、フロントエンド・バックエンドを意識しないコーディングができるというものであるが、それよりもオフラインでも使えるといったユーザエクスペリエンスの方が重要だと思う。
Isomorphicはほどほどに、ユーザエクスペリエンスを高めつつ、密結合にならないような現実解を見つけていければと思う。














{kind=link}