

昨日の記事はちょっとわかりにくかったと思うので補足したい。
RDB不要論
浅海先生よりコメントをいただいた。(ありがとうございます)
CQRSも、伝統的なオンラインとバッチによるアプリケーション・アーキテクチャに新しく名前をつけたと考えると過去との技術の連続性も見えてきて面白いところ。よく考えてみると昔から普通にやってきたことだよなぁ、と。もちろん登場人物が変わってきているので新しい革袋に入れなおす必要はある。
— 浅海智晴さん (@asami224) 6月 28, 2012
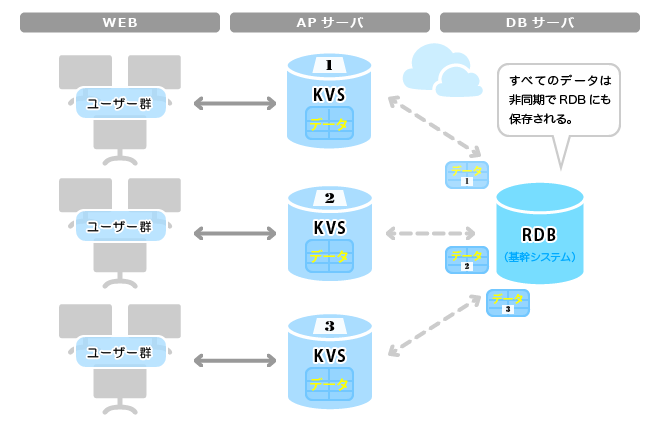
全くおっしゃるとおりで、「昔から普通にやってきたこと」で今でも大変有効な技術は多いと思う。ISAMやVSAMのKSDSにしても昔は実際にオンライン処理をやっていたわけだからできないはずがない。というより、もしかしたらRDBより向いているんじゃないか?というのが私の率直な印象。結局のところ、データの集計や分析では、わざわざRDBからデータ抽出してHadoopでバッチ処理するか、カラムナDBに入れ直すとかやっているわけである。実際、大規模トランザクションを処理するオンラインシステムでは「リレーショナル」機能はほとんど利用されておらず、まるでKVSのように使われているのが現状ではないだろうか。そう考えると、そもそもオンライン処理でリレーショナルは必要ないんじゃないかとさえ思えてくる。
それからもっと厄介なのがO/Rマッピングの件。オブジェクトの構造や関係性をリレーショナルモデルに効率よく変換できない問題(インピーダンス・ミスマッチ)があって、その結果作られた効率の悪いSQLが全体のパフォーマンスを劣化させてしまうという現状がある。
なので、やはり、O/Rマッピングなどの「癌」はアプリから排除すべきであり、そのためにはRDBではなくオブジェクトを直接ストアできるKVSを使うべきというのが私の意見である。それでやっと純粋にオブジェクトの世界だけでアプリを作れるようになるのだ。
また他方で、RDBはオンライン処理系から排除されてバッチ処理系の仲間になるわけだが、これは前述したとおり、カラムナDBにするか、いっそのことHBASEにしてしまうのがいいのではないかと思っている。そして、バックエンドのHBASEなどに対しては、今流行のFluentdを利用することで、うまくやれば、ほぼリアルタイムに更新可能になるかもしれない。ただし、データロスは許されないので信頼性の担保についてはもう少しよく検討する必要があるとは思うが。
これでいいのだ

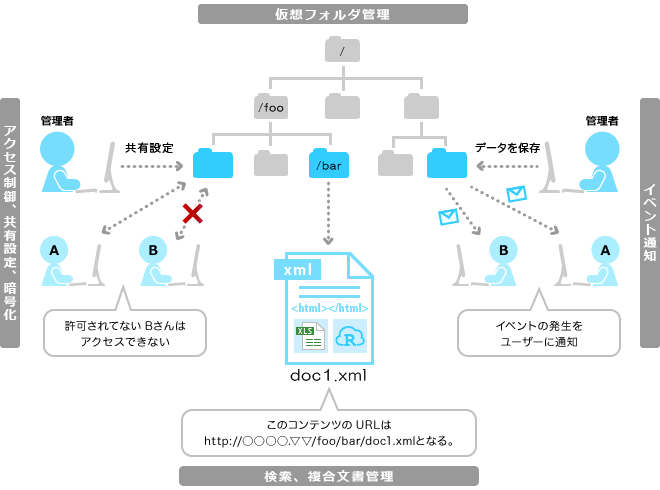
そこで、ツリー構造の仮想フォルダ管理とREST APIによるデータアクセスで解決することを考えた。実際にReflexWorksでは、以下のように、UNIXのファイルシステムのパスのようなイメージで直感的に操作でき、アクセス制御、共有設定、暗号化といった設定も可能である。例えば、GET /foo/bar/doc1.xml と実行すると、doc1.xmlを取得できる。(GETコマンドはリモートからのHTTPリクエストかローカルのAPIからのどちらからでも実行できる。また、doc1.xmlはATOM Entryを拡張したもので、様々な項目をユーザ自身で自由に追加できる。もちろんJSONも可能だ)ちなみに、GET /foo/bar とすると、barフォルダ配下のエントリが全てリストで取得でき、?item=hello* など、項目に検索条件を指定することも、前方一致検索、ソートなども可能だ。アプリで必要な機能はほぼ満たしており、リレーショナルを意識することなく、オブジェクトに集中して設計開発できるのは大変嬉しいところである。
それからもっと厄介なのがO/Rマッピングの件。オブジェクトの構造や関係性をリレーショナルモデルに効率よく変換できない問題(インピーダンス・ミスマッチ)があって、その結果作られた効率の悪いSQLが全体のパフォーマンスを劣化させてしまうという現状がある。
なので、やはり、O/Rマッピングなどの「癌」はアプリから排除すべきであり、そのためにはRDBではなくオブジェクトを直接ストアできるKVSを使うべきというのが私の意見である。それでやっと純粋にオブジェクトの世界だけでアプリを作れるようになるのだ。
また他方で、RDBはオンライン処理系から排除されてバッチ処理系の仲間になるわけだが、これは前述したとおり、カラムナDBにするか、いっそのことHBASEにしてしまうのがいいのではないかと思っている。そして、バックエンドのHBASEなどに対しては、今流行のFluentdを利用することで、うまくやれば、ほぼリアルタイムに更新可能になるかもしれない。ただし、データロスは許されないので信頼性の担保についてはもう少しよく検討する必要があるとは思うが。
これでいいのだ
データ操作と破壊的イノベーション
リレーショナル機能がないとしたら、データ操作をどうするかという問題が出てくる。RDBはなんだかんだいって、複合検索やソート、JOINといった、とても便利な検索が可能である。そして、これはアプリにとって大変重要で必要不可欠な機能でもある。そこで、ツリー構造の仮想フォルダ管理とREST APIによるデータアクセスで解決することを考えた。実際にReflexWorksでは、以下のように、UNIXのファイルシステムのパスのようなイメージで直感的に操作でき、アクセス制御、共有設定、暗号化といった設定も可能である。例えば、GET /foo/bar/doc1.xml と実行すると、doc1.xmlを取得できる。(GETコマンドはリモートからのHTTPリクエストかローカルのAPIからのどちらからでも実行できる。また、doc1.xmlはATOM Entryを拡張したもので、様々な項目をユーザ自身で自由に追加できる。もちろんJSONも可能だ)ちなみに、GET /foo/bar とすると、barフォルダ配下のエントリが全てリストで取得でき、?item=hello* など、項目に検索条件を指定することも、前方一致検索、ソートなども可能だ。アプリで必要な機能はほぼ満たしており、リレーショナルを意識することなく、オブジェクトに集中して設計開発できるのは大変嬉しいところである。
RDB不要論とか偉そうに言っているが、実はこういった発想はGoogle AppEngineからいろいろ学んで得たものである。ひがさんの記事の破壊的イノベーションのような発想の転換があり、それから、コスト1/30でスケーラビリティの衝撃 で紹介したような実際にKVSで動作するスケーラブルなアプリが多数作られるにつれ、自信が確信に変わっていった・・。
CQRSとの比較
で、CQRSの話に移るが、恥ずかしながら、浅海先生から指摘されるまで知らなかった。CQRSとは には以下のようにある。
CQRSは「Command Query Responsibility Segregation」の略語である。日本語で言えば「コマンドクエリ責務分離」もっと解りやすく言えば「更新処理と参照処理とに対する応答部分を明確に分離する」事である。構造としてSystemを次の四つに分類する。
- Query(参照)
- Command(更新)
- 内部Event
- 外部Event(公開Event)
これを読む限りにおいては、ReflexWorksはCQRSではないようである。
更新処理と参照処理はKVS内で完結するため分離ではなく同一である。KVS内であれば参照と更新を分けなくても高速に処理できる。どちらかというとRDBの負荷を軽減させるというよりRDBを無視して単独で動作するという表現に近い。また、MVCを否定しているわけではなく、MVCモデルは進化する で述べた以下の発想に基づいて設計されている。
ドメインサービスとしてのReflex BDBReflexの新3層アーキテクチャーにおけるドメインは、EntityのCRUD操作以外の何ものでもないのだが、登録変更削除においては、「外から何をされてもデータの整合性が壊れない様にすること」がもちろん保証されなければならないし、検索においては、単なるPKによる検索だけではない点は補足すべきだろう。例えば、PK以外のKeyによる検索、大小比較、全文検索、Pagingといった検索などについては、要求仕様に応じて、それなりにドメインロジックを実装しなければならない。 まだ公表する段階ではないのだが、Private CloudのソリューションであるReflex BDBの次のバージョンにおいて、単なるKey/Valueの検索ではなく、ドメインサービスとして機能するようなものを作っている。内部的にはBDBなのでKey/Valueではあるが、GAEのProperty Indexのような仕組みを追加することで、汎用的なKeyによる検索などができるようにするつもり。ちなみに、これはConsistent Hashと伝染プロトコルを使ったスケールアウトアーキテクチャーとなっており、Dynamoのようにそれぞれのノードを柔軟に追加削除できる。(予定)

この記事を書いたのが2009年10月で、完成してお客様事例になったのが2011年1月だから、まともに使えるようになるまで2年以上かかったことになる。現在、事例1 のお客様で










{kind=link}