skip to main |
skip to sidebar
トランザクションは意識しないのが一番
歴史は繰り返すんだろうか。トランザクションに関しては、こんな感じで話がループしている気がしている。
1) トランザクション宣言を明示的にコードに記述(ホスト、ODBC/JDBC)
2) 生産性が低くなり新しいフレームワークが出現(EJB、Seasar2)
3) 新しいイノベーション誕生(cloud)、トランザクションを明示的に宣言、以下繰り返し
トランザクションについては、2年前にも一度述べたことがある。実装が難しく不具合になりやすいので、生産性、品質を上げるには、開発者にトランザクションを意識させないことが一番である、といった感じのことを書いたつもりであった。
【EC開発体験記-トランザクション処理-】古くて新しい永遠のテーマ
GAEにおいても方法論は異なるとは思うが、開発者にトランザクション処理を意識させたくないという私のスタンスは今でも変わっていない。GAEにもそのうち新しいフレームワークが現れて生産性が高くなっていくかもしれない。
でもエンジニアの性というか、トランザクションを議論するのは、いつの時代でも好まれるようである。何百時間とかけて、そのくせ不完全だったりする(私も例外ではない)。
モデリングの話もそうだったが、エンジニアは基本的に穀潰しである。
とはいえ、過去の考え方をあらためて学ぶことは、それはそれで有益に思えることもある。 ということで、一応、復習することにする。
トランザクションコンテキストは野球のボール
EJBが登場したとき、メソッドの呼び出しだけで、何でトランザクション処理が可能になるのかわからなかった。実はコンテナがメソッドを管理していて、呼び出し時にトランザクションコンテキストの受け渡しを行うことで実現していたのだが、これを理解できたときはとても感動したものだった。(しかし、重いEJBはパフォーマンスが悪かったので普及せず、Seasar2がそれを改善した。AOPによりトランザクションを実現しているのを知ったときは一本取られたと思った。)
で、その具体的な仕組みを説明する。
トランザクションコンテキストは何かというと、マジックで番号が記入された野球のボールのようなものと考えればよい。担当者に仕事を依頼する際に、受付番号を書いたボールも一緒に渡すことにして、もし担当者が処理に失敗した場合は、ボールに×を書いて返すようにする。担当者は別の担当者に再委託もできるが、その際にも必ずボールも渡すこととする。最後に依頼者にボールが戻ってきたときに、×が付いているかをチェックして、処理の成功失敗を判断する。成功であればその受付番号の処理を最終的にコミットとする。失敗であれば何もしないでボールを捨てる。受付番号が記入されているので同時並行処理が可能なのである。
受注と在庫引当を分散トランザクション実行
以下は、分散トランザクション実行のアイデアである。(このBlogでは、受注とか在庫とかのEC単語が唐突に出てくる。)上記のトランザクションコンテキストを受け渡す方法を元に考えたものだ。図には書いていないが、TaskQueueによる在庫引当では冪等性(べきとうせい)も考慮する。
受注受付のタイミングと在庫更新のタイミングは異なるが、2重引当などの致命的な問題は起こらないはずである。ただ、実際より在庫が少ないとみなされる瞬間がある。
ブラウザーでステータスを確認するか、ステータス更新時にメールするなど、基本的にはステータス参照で対応するところが非同期の特徴である。
なお、口座送金処理といったものへの応用は、もしかしたら可能かもしれないが、参照のタイミングが一致しないので、この方法ではたぶん無理だと思う。

世界的な不況が続く中、競争力のある強い体質の企業になるためには、大幅なコスト削減が必要である。とりわけ、ITシステムへのコスト削減圧力は大きく、これに対応するためには、アーキテクチャー見直しや内製化などを含め、抜本的な改善していかなければならない。
Privateクラウドは、ITシステムのコスト削減の一手段として考えることができ、こういった課題に対応できる可能性をもつと考えられる。
今回は、Privateクラウドをテーマに思うところを述べてみたい。
Privateクラウドはクラウドではない?
11/22の日経新聞にクラウドの特集があった。
そこには、クラウドの定義ははっきりしないが、「ネットの向こう側にあるソフトなどのIT資産を使う」という概念が基本となると書いてあった。また、誤解に関して以下のような感じで書かれてあった。
クラウドがブームになり、最近は関連する一部技術を入れ込んだだけのサービスにもその名が付く。「企業内クラウド(プライベートクラウド)」。「仮想化」という技術を企業内のIT資産に適用したもので、効率的な社内システムを構築できるが、「ネットの向こう側」を利用するクラウドの本質からは外れている。こうした拡大解釈が広がれば、利用者の誤解を招きかねない。利用する側も注意が必要だ。
まあ、クラウドは一般的には「ネットの向こう側」と解釈されるのだろう。
でも私は、クラウドの本質と動向にも書いたとおり、あくまで「抽象的に定義されたデータベースサービスへのアクセス手段」と考えていて、また、べらぼうに安いこと、およびリニアにスケールすること、の2つのポイントも重要だと考えている。なので、企業内にあっても外部にあっても、上記が満たせるのであれば別にクラウドと呼んでもいいと思っている。別に「ネットの向こう側」になきゃいけないわけではない。具体的には、今後はDHT(Distributed Hash Table)技術を使った分散KVS(Key Value Storage)などを応用したものが企業内クラウドの代表的なものになっていくんじゃないかと考えている。
一方で、「ネットの向こう側」にありながら、全然安くないクラウドもたくさんある。GAEやAmazonEC2などは、CPU時間あたり$0.10、Storageは$0.15 (GB/Month)でほぼ足並みをそろえているのに対し、日本の某通信会社のPublicクラウドは十数万円と2桁の差がある。利用する側が注意しなければならないのは実はこっちの方である。
企業内クラウドもコストとスケーラビリティは重要
分散KVSといったクラウド技術を企業内システムに応用することで得られるメリットは、コスト削減とスケーラビリティ向上の2つである。
まず、トランザクション増加に対応するためには、ノードの追加だけでリニアにスケールするような仕組みが重要である。それから、基幹システムであるからにはAvailabilityも重要となる。一部が故障しても自動的に切り離されて問題なく動作しつづけるような高可用性システムをいかに構築できるかが鍵となる。
コスト削減効果として期待できるところは、コモディティサーバとオープンソースの活用によるインフラコストの削減である。実際に、ノードはIAアーキテクチャでLinuxベースのコモディティサーバを使えばいいし、ソフトウェアに関しては、実際に動的なノードの追加削除を可能とするDynamoクローンのオープンソースもある。このように、クラウドの仕組みを、今ではコモディティサーバとオープンソースで実現できる。
2点目は、内製化により「脱ベンダー依存」ができるという点。つまり、コモディティサーバとクラウド技術を活用したオープンなアーキテクチャーを構築することで、ITベンダーの固有のアーキテクチャーに依存しないシステムを構築することが可能になるということ。これまでベンダーによる見積もり(お手盛り)をせいぜい値引きするぐらいしかできないのが現状であった。
オープン技術の組み合わせでエンタープライズシステムを構築できれば「脱ベンダー依存」が進み、ベンダー独自の技術に依存してきた弱みから脱却できるようになる。
ITベンダーによるボトムアップ提案から利用者自身によるトップダウン調達。コモディティサーバなどの部品調達レベルの取引になっていくことで、エンタープライズシステムの価格破壊は必至となる。
価格シミュレーション
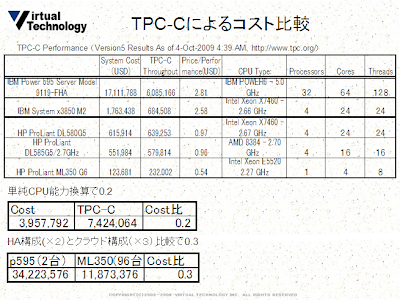
実際にどれくらい安くできるのかを調べるため、具体的にTPC-Cベンチマークを元に価格比を計算してみた。
1) Scale-up型の最高モデルであるIBM p-595とコモディティサーバHP ML350とを比較すると、単純CPU能力換算でCostは1/4となる。
2) HA構成(マシンは2台)とクラウド構成(マシンは3台)で比較するとCostは1/3となる。(クラウド構成でマシン3台を根拠とする理由は、Quorumプロトコルで推奨されるのがN:R:W=3:2:2であること。実際のDynamoの冗長ノード数が3台であることなど)
もちろん、場所代や電気代など、計算に含まれない要素はある。極めて一面的な見方しかしていないが、PrivateクラウドのHWコストメリットは、ざっくり、1/3~1/4となる。
面白いのは、IBMの機種どおしで比較してもコストメリットは見出せないということ。おそらく、全プラットフォームでPrice/Performanceが2.5前後になるような戦略的な値を設定しているのだろう。
もう一つ、特筆したいのがHWに及ぼす影響についてである。
クラウドは、Scale-up型のハイエンドサーバから、Scale-out型のIntel Xeonベースのコモディティサーバへの変化をもたらし、さらには、FAWNといったようなローエンドプロセッサとフラッシュメモリのクラスタへの変化を促すだろうと考えられている。そして最後には、シングルチップ・クラウドコンピュータへの進化に行きつく。クラウドのイノベーションは、複数のCPUが疎結合で連携するような処理を、1チップのなかで実現することを可能にする。

クラウド化による新たな課題
安価なハードウェアの導入とオープンソースの利用を中心とした、エンタープライズ・システムのコモディティ化は、コスト面やスケーラビリティにおけるメリットが大きい一方で、以下の新たな問題を生むこともわかっている。
1)リスクを利用者自身が負うことになる
2)システムが複雑になる分、運用管理が大変になる
脱ベンダー依存を成し遂げたら、すべての責任は利用者自らが負うことになる。これまで、システムの調子が悪かったら何でもかんでもベンダーの責任にできたところが、そうはいかなくなり、自分自身で大きな不安と苦しみを抱え込むことになる。
また、これまでの2~3台であったシステムが100台近くに増えると、運用の仕組みが大きく変わってくる。例えば、バックアップを取る際には、全ノードを一旦Read Only状態にしたうえで実行しなければならない。また、ソフトウェアの配布などを100台一斉に実行するような仕組みも必要になってくるだろう。このあたりは実際に運用してみると、もっと大きな課題が出てくると思われるが、いずれにしても運用をいかに効率よくやっていくかが重要なポイントであることは間違いない。(Googleはこの点がすばらしいと思う)
マイクロソフトとAzure戦略
日経新聞のいうところのクラウドの本質は「ネットの向こう側」を利用することであった。前述したように、私から言わせれば、PrivateとPublicの違いはコストだけなのだが、コストメリットだけ考えると、Publicクラウドの利用は大変魅力的であり、エンタープライズにおいて活用できれば非常に大きな競争力となるのは間違いない。とにかく、Publicクラウドはべらぼうに安い。
AmazonやGoogleには、それぞれがEC、検索エンジンといった本業をもっていて、システムの余剰なリソースを貸し出せるという利点がある。もちろん、スケールメリットがあり、電力効率などを含めたデータセンターの効率的な運用数値PUEがずば抜けてよいことも知られている。
当分の間は2強の時代が続くと思われるが、猛烈に追随しているマイクロソフトのAzureも気になるところである。繰り返しになるが、ポイントはコストとスケーラビリティの2つ。安さという点で2強を追随できるのか、あるいは、スケーラビリティの点で優れた技術を提供できるのか。
本来、Windowsはコンシューマから発展したOSで、基幹システムでの利用が進んでいるとはいえ、ミッションクリティカルで大規模なシステムはあまり得意ではなかった。前述したような、IBM p-595サーバとは、比較すらできなかったのであるが、Azureでもってスケーラブルシステムが構築できるようになれば話は別である。セキュリティ、コストといった課題はあるものの、エンタープライズに踏み込める可能性がさらに大きくなったといえる。
<追記>
日経BPの中田さんによるAzure IT PACの写真
<関連>
Chrome OS戦略とIT世界の対立軸
Request was aborted after waiting too long が出る理由
前記事の実行結果を見てもらえばわかるとおり、"Request was aborted after waiting too long・・"というエラーのせいで、処理が中断されてリトライが頻発しているものが多くある。これがTaskQueueのスケーラビリティを阻害しているのは間違いない。これは、queryの実行時間が10秒を超えると出るようである。(PDF生成処理Taskでは10秒を超えるものがあるのでtaskの経過時間というよりqueryの実行時間によるのだと思う。たぶん)
別にquotaを上回るような処理を流したつもりはないのになぜ出るのか。
この現象については、ココでも質問されているが、Googleからの返事はまだない。
total queue execution rateの定義
Taskの実行時間が10秒を超えるとキャンセルされる、とはどこにも書いていないので、エラーメッセージにあるとおり、何かしらquotaを上回る処理があって、それが原因で待ちが発生して、これ以上待つのは無理だからキャンセルされた、というふうに理解していた。quotaといっても、ココにあるように、いろいろあるが、私は、total queue execution rateが一番あやしいと思っている。
MLでJamesさんが自己レスしているが、total queue execution rate が 20 task invocations per second というのは、dequeueするtaskの数ではなく、処理可能なquery数ということらしい。つまり、taskqueueを使って処理できるのは最大20qps/sということ。これなら(納得はできないが)理解はできる。
この件に関して、ありがたいことに、ひがさんからコメントいただいた。このあたりの話は、GAE Nightでいろいろ聞くことにしよう。
あのwarningは、リクエスト処理中に後続のリクエストが来てqueueにつまれ10秒以内に処理されなかったときに発生します。
つまり、AppEgnineは30秒ルール以外にも、負荷が集中するときには、10秒以内に処理しないければいけないという10秒ルールも存在するのです。
10秒ルールを守ったとしても完璧にスケールするかはまた別の話ですが、今のAppEngineの能力を最も引き出せるということはいえると思います。
エラーが発生する原因
「Request was aborted after waiting too long 」が出る原因を考えてみた。
仮定1)同じインスタンス(同じVM上アプリ)に複数のリクエストが入ろうとして待たされている。
仮定2)spin up(アプリケーションの起動)までに時間がかかるのが原因。例えば、cold start時には、まっさらなVMにクラスをロードする時間などが余分にかかる。それが加算される。
これを突き止めるために、以下の実験をやってみた。
実験1) 同じvmであればEnQueueしなおしてすぐに終了させるようにするとどうなるか
実験2) 新規のvmhashの場合、一回目はすぐに終了させるとどうなるか

同じVMであるかどうかは、こちらの記事にあるとおり、Runtime.getRuntime().hashCode()を比較することで判別するようにした。(memcacheを使ってhashcodeを管理する)
そしたら、hashcodeが重なってた(下図)ので、こちらの記事のように、ServletContext+UUIDで判別するようにした。

実験結果
前記事の全文検索アプリを使って実験した結果、以下のようになった。
- 1タスク500件、一度に4タスク登録。(合計20タスク)
- 全データ検索まで : 1分41秒
- 1タスクの処理時間 : 5~7秒
- ただし、初期起動の場合は8~9秒
- RuntimeのhashCodeが同じでも、違うuuidが最初に起動する場合、8~9秒かかる。
- "Request was aborted ..."が1回出現。
- 起動チェックをRuntimeのhashCodeでなく、uuidで行う。
- uuidごとだと仮定1(複数のTASKが同じVM(マシン)で実行される)は起こらないので、実験1は行わない。実験2のみ行う。
- 以上の条件で、1タスク500件、一度に4タスク登録。(合計20タスク)
- 全データ検索まで : 1分4秒
- 1タスクの処理時間 : 6~7秒
- 起動インスタンス : 4個
- "Request was aborted ..."のWarningログは1回も出力されていない。
- 1タスク500件、一度に8タスク登録。(合計20タスク)
- 全データ検索まで : 1分6秒
- 1タスクの処理時間 : 6~7秒
- 起動インスタンス : 4個
- "Request was aborted ..."のWarningログは1回も出力されていない。
- 1タスク500件、一度に16タスク登録。(合計20タスク)
- 全データ検索まで : 1分34秒
- 1タスクの処理時間 : 6~7秒
- 起動インスタンス : 5個
- "Request was aborted ..."のWarningログは1回も出力されていない。
- 1タスク1000件、一度に4タスク登録。(合計10タスク)
- 最初にリクエストして約5分経過しても、1個のタスクも終了しない。
- 新しいインスタンス起動 : 22回
- 実験2)新しいインスタンスの場合QueueにTaskを登録し直してすぐに終了する、という処理は正常にできている。
- "Request was aborted ..." : 18回
- なぜかQueueのTaskが4個から9個に増えた。(プログラムバグ?)
- TaskQueueの設定を変えてテスト。rate=10, bucket size=10に設定。
- 4タスク : 1分4秒
- 8タスク : 58秒
- 16タスク : 1分12秒
- 16タスクの場合のみ"Request was aborted ..."のWarningログが数件出力されている。
- TaskQueueの設定を変えてテスト。rate=10, bucket size=20に設定。
- 4タスク : 1分5秒
- 8タスク : 1分
- 16タスク : 1分22秒
- 8,16タスクの場合"Request was aborted ..."のWarningログが数件出力されている。
- 1タスクあたりの処理件数を変えてテスト。(TaskQueueの設定 : rate=10, bucket size=10、一度に4タスク登録)
- 700件(合計15タスク) : 2分54秒
- 1タスクの処理時間 : 8秒~10秒弱(10秒は超えていない)
- "Request was aborted ..." : 4回
- 600件(合計17タスク) : 1分57秒
- 1タスクの処理時間 : 7秒~8秒
- "Request was aborted ..." : 2回
- 400件(合計25タスク) : 57秒
- 1タスクの処理時間 : 4秒~6秒
- "Request was aborted ..." : なし
- 300件(合計34タスク) : 1分2秒
- 1タスクの処理時間 : 4秒~5秒
- "Request was aborted ..." : なし
- 200件(合計50タスク) : 1分16秒
- 1タスクの処理時間 : 2秒~3秒
- "Request was aborted ..." : なし
- まとめ
- uuidごと(ServletContextごと)にcold startされている。
- Taskの処理時間が10秒を過ぎると"Request was aborted ..."とWarningログが出力され、リトライされているようだ。
- 仮定2)cold startの場合はQueueに再度処理を登録し直して自分は終了する、という方法は、しない場合と比べて速くなった。
- cold startの場合は処理時間が10秒を超えてリトライされていたためと推測される。
- インスタンスは4~5個立ち上がるが、同時に処理を行うのは最大4個。
- 1タスクあたりの処理時間が4秒~6秒以下の場合、Taskの同時処理数が4個で安定する。
10秒近くなるとTask同時処理数が減ってくるため、総処理時間が遅くなる。
- 1タスクあたりの処理時間を4秒~6秒とすると、総処理時間が最も速くなった。
エラーメッセージは出ないようになったが、相変わらずインスタンスの最大が4つというところが納得いかない。
TaskQueueを使ってPDFを生成する
先の記事で疎結合、バージョニング、非同期がスケーラブルにするための要素だと述べた。私たちが提供するReflex iTextサービスでは、PDF生成サービス(図中 pdfservice)やデータサービスなどは、独立したサービスとして立てられる。独立したサービスは(カッコつけていえば)サービスコンポーネントとして考えることができる。サービスコンポーネントは、ServiceとReferenceの2つの口をもち、いわゆる芋ずる式に(疎)結合できる。そして、TaskQueueを利用することで、それらを非同期かつ並列に実行することができる。これを、ぶいてく流サービスコンポーネントアーキテクチャーと呼んでいる。

例えば、請求書アプリでは、
http://invoice.latest.reflexcontainer.appspot.com/invoice?invoiceNo=DEMO1&xml
でGETすることで、データサービスからデータを取得することができる。(&jsonとすることでjsonも取得も可能)
そして、以下のようにデータとtemplateを同時に与えることでPDFを生成する。内部的には、pdfservice(service)に与えられたurlを元に参照(reference)を実行している。
http://pdf.latest.reflex-itext.appspot.com/pdfservicegae?template=http://invoice.latest.reflexcontainer.appspot.com/invoice.html&entity=http://invoice.latest.reflexcontainer.appspot.com/invoice?invoiceNo=DEMO1&xml
さらに、TaskQueueによって起動された複数のTaskからこのリクエストを実行すれば、大量のPDFを瞬時に生成することができる。これは以下のような仕組みになっている。

スケールしない現実
だが、ココや、ココに書いたとおり、実際にはスケールしない。
700ページを12リクエスト(合計8400ページ)処理させた場合について計測してみると、unit=70の場合(700/70*12=120タスク)で約15分かかってしまう。unit=70の場合で1タスクの処理時間が30秒未満なので、本当に並列処理されているとすれば、30秒で完了しなければならないはずである。ちなみに、unitの数と処理時間の関係は以下のとおりである。unit=50で最速であるが、それでも1分かかっている。
- 1 : 生成(全タスク完了まで)
- 2 : 取得(PDFマージ処理からクライアントで文書を開くまで)
- unit=70,total=700 (タスク件数 : 10件)
- 1分20秒,1分10秒
- 57秒。42秒
- unit=60,total=700 (タスク件数 : 12件)
- 1分20秒。
- 1分。
- unit=50,total=700 (タスク件数 : 14件)
- 1分2秒,1分15秒。
- 1分4秒,47秒。
- unit=40,total=700 (タスク件数 : 18件)
- 1分15秒。
- 54秒。
- unit=30,total=700 (タスク件数 : 24件)
- 1分20秒,1分35秒,1分14秒。
- 50秒,43秒。
- unit=10,total=700 (タスク件数 : 70件)
- 1分52秒,1分33秒。
- 52秒,50秒。
詳細分析
- どれも以下のWarningが多発
Request was aborted after waiting too long to attempt to service your request. Most likely, this indicates that you have reached your simultaneous active request limit. This is almost always due to excessively high latency in your app. Please see http://code.google.com/appengine/docs/quotas.html for more details.
TaskQueueのワーカー側から出力されている様子。
2個目の終了ログの前に上記ログが複数出力されているケースが多い。
処理の合間にもちらほら出力される。
Maximum RateとBucket Sizeを下げる(どちらも5に設定)と、abort発生頻度が下がる。
- 1はインスタンス2個、2,3はインスタンス3個
- 全ての処理が終了するのは、どれも15分程度で変わらない。
- あるインスタンスが最初に処理を行う場合、2回目以降と比較して処理時間が長い。
- 一度に4個程度並行処理を行っている。そのうち3個は同じJVMで、1個だけ別のJVMというパターンが多い。
- また、クライアントから連続してリクエストを投げた際(今回のテストでは4秒間隔)、エラーが時々発生する。1回目のリクエストは成功し、2回目のリクエストでエラーが発生することが多い。
ボトルネックがどこにあるかわからなかったため、下図のように、Memcacheにデータを格納することで、ネットワークI/Oをなくすケースについても計ってみた。

- TaskQueue処理データをMemcacheに登録するテスト
- 1Taskあたり700ページ作成すると、dispatcherでの処理で以下のエラーが発生してタイムアウトする。240~300ページあたりで、エラーになったり正常終了したりした。
- jp.reflexworks.pdfservice.PdfDispatcher doGet: com.google.apphosting.api.DeadlineExceededException: This request (789cb38865d5e3d2) started at 2009/10/27 06:10:31.448 UTC and was still executing at 2009/10/27 06:10:59.946 UTC.・・・
- 8400ページ出力処理(以下、1Taskあたり240ページ作成とする)
TaskQueueのMaximum Rate : 5.0/s、Bucket Size : 5.0に設定。
- unit=20,total=240を35回リクエスト(クライアントからのリクエスト間隔:4秒)
- タスク数は、12×35=420個。
- 1タスクにつき処理時間が6~11秒かかる。
- 実行結果
- dispatcherへの1回目のリクエストはエラーになった。2回目から正常終了。
- やはり"Request was aborted ..."のWarningが所々出力されている。(4回正常、1回Warningログというパターンが多い)
- dispatcherの応答時間が長い。
- Memcacheを使わない場合は2~7秒、今回は9~10秒。
- 1タスクあたりの処理時間は、Memcacheを使わない場合とあまり変わらない。
- 総処理時間は19分。(エラー分の2回を追加でリクエストした。)
- VM起動数は4個。
- リクエストを投げ終わる時間は10分。
この結果でわかることは、
1)リクエストを投げ終わる時間は10分だが、リクエストを投げてから、すぐにTaskが起動されるため、Task処理開始から終了までにかかる時間は19分である
2)1タスクの処理時間に変化がなかったことで、一括検索+Memcaheに格納のメリットは見い出せなかった
3)1回目のリクエストでエラーとなるケースが多い(この件については、次回の記事にて、詳細に分析した結果を報告する)
ちなみに、TaskQueueを使わないで、すべてdispacheで処理したケース(つまり、多重度1)では、
- 8400ページ出力処理、クライアントからのリクエスト間隔を0秒にしてテスト
- リクエストを投げ終わる時間は7分。
- dispatcherへのリクエストは、35回中2回エラー
- 総処理時間は19分。(エラー分の2回を追加でリクエストした。)
また、MemcacheのI/O回数を減らし、20件分をまとめてgetしたケースでは、
- Memcacheへのデータ登録単位を1件からunit(20)件にし、Task側ではMemcacheからgetする回数を1回にしてテスト
(Memcacheに、1個のキーに対しデータunit(20)件分のjson文字列を格納する。)
<続く>
<追記>
・ 軽いWorkerタスクを別途用意して連続して負荷をかけることでVMは16程度起動することがわかっている。今度はServletContext+UUIDで負荷分散状況を調べてみた
・ WdWeaverさんの実験 スケールアウトの真実
ぶいてく流スケーラブル設計3大要素
私たちがスケーラブルなアプリを作る際に重要だと考えている要素は、疎結合、バージョニング、非同期の3つである。
今回は、疎結合、特にバージョニングについて詳しく述べる。非同期(TaskQueue)は次回の予定。
疎結合
GAEといったスケーラブルなプラットフォームを利用することで、単純なWebアプリでもスケーラビリティを得られるわけだが、さらにそれをRESTfulなWebサービスにすることで、より柔軟なスケーラビリティを享受できる。マッシュアップアプリがいい例で、ワンソース・マルチビューを実現できる。それは、この記事や、実装例で示してきたとおりである。これらはReflexやReflexGaeフレームワークにより、EntityからJSONやXML等に変換することで実現している。
バージョニング
この記事の最後の一文は、なんのこっちゃ!?と思った方も多いと思う。
「ただし、これをやるには、レコードをRevision番号で管理するという前提で考える必要があり、更新において新しいRevision番号でレコードを追加する必要がある。」
要はバージョニングのことなのだが、その目的は、楽観的排他によるスケーラビリティの向上と、履歴管理によるトレーサビリティの向上の2つである。削除したデータも保存しておくことでUndo機能もつけることができる。
楽観的排他はロックを起こさないのでスケーラビリティ向上につながる。つまり、更新の際にRevison番号を比較することで不整合を起こしていないかチェックする仕組みで、それをアプリレベルで実装しようというものである。
HTML5のDataStorageのように、疎結合、非同期を前提とした「いまどき」のアプリでは、ブラウザで何かアクションを起こしても、すぐにはサーバに問い合わせにはいかない。そうなると不整合を起こす可能性も大きいわけだが、レコードがバージョニングされてさえいれば、整合性を解決することはそれほど難しくない。Revison番号が同じレコードは常に同じ内容であることが重要で、また、サーバのDatastoreやMemcache、あるいはクライアントのStorageなど、どこにあろうと同じものとして扱われることになる。もし同じRevisionで異なる情報があったとしたらDatastoreの内容を正とすることで整合性は保たれる。したがって、クライアントに存在する情報とサーバにある情報は時間差こそあるものの、全体的に見ると常に整合性が取れた状態とみなすことができる。(これが私が理解している、Eventually Consistencyの概念だ)
というわけなので、オフライン時はクライアントのStorageを読みこめばいいし、オンラインでもMemcacheにデータが残っていればそれを返せばいい。そのとき最新のRevisionがDatastoreにあったとしても、神経質にならずに、Memcacheのタイムアウトまでは古い情報であっても返しちゃえばいいのだ。もちろん、在庫引当や座席予約など、このやり方が通用しない要件はあるが、ほとんどは「遅延」を許容できるアプリと思うので、このように実装することでスケーラブルになることは間違いないと思われる。(そういえば、DatastoreのIndex作成も遅延が起きるような・・appengineはRead Committed相当だがcommit()には2つのマイルストーンがあることを忘れてはいけない)
関連として、レコードにシーケンス番号をつけることも挙げておく。これは、Pagingや件数管理のために使用する。シーケンス番号をつけることで、最新レコードを取得できるようになる。また、大量のレコードを分割してTaskQueueで並列処理させたい場合には、シーケンス番号で範囲指定を行える。
件数管理は、GAEは件数を数えるのが苦手で数十万件以上になるとタイムアウトを起こして検索できなくなるので、最新レコードで常に管理しておこうというアイデアである。
最新レコードのQueryは件数に影響されずにそこそこ高速に検索できる(約0.6s)ことを利用している。
削除済みデータなど、不必要に思える(むしろ消すべきと思える)ものを残して履歴管理する第一の理由は、データ量がパフォーマンスに影響しないということ。その点は特に強調したい。
以下に、バージョニングのロジックを示す。大福帳管理モデルというのは私が勝手につけた名前で、あまり人に吹聴するとイタイ目にあうかも。multidimensionalの方が近い意味だと思う。
大福帳管理モデル(別名:カーボンコピーモデル 英語名:multidimensional)
- 大福帳管理モデル(multidimensional,カーボンコピーモデル)(勝手に命名)
- 楽観的排他でスケーラビリティ向上
- 履歴管理によるトレーサビリティ向上、Undo機能
- 件数管理によるパフォーマンス向上
- すべてのレコードは、Key+Revison番号で管理される。
- Key(※)+Revisonが同じであれば、同じ内容のレコードであるとみなす。ただし、削除は例外扱い。(※このKeyはアプリのキーでありDatastoreのKeyではない。詳細は、ココのKeyに何を入れるべきかを参照のこと)
- 追加では、レコードが存在しなければ、Revisonを0にセットして追加する。レコードが存在していれば、エラーか強制登録を実行する。強制登録は、削 除フラグが立っていることを確認して、revisonを+1したうえで追加する。このとき削除フラグが立っていなければエラーとする。この処理は GET/PUTによるトランザクションで実行されなければならない。
- ただし、強制登録では一度削除されたものと同じKeyでの再登録をすることになるので、それを許すかどうかはアプリの要件による。(Forceオプションか何かで区別すべき)
- 更新では、現在のレコードがあることを確認して、更新レコードのRevisonと同じであるかチェックする。NGであれば楽観的排他エラーとする。OKで あればRevisonを+1して更新すると同時に現在のレコードには削除フラグを立てる。この処理はGET/PUTによるトランザクションで実行されなけ ればならない。また、現在のレコードに削除フラグが立っていてもエラーとする。(これで既に削除されているときの楽観的排他ができる)
- 検索ではRevison番号は更新されない
- 削除は論理削除であり実際には消さない。削除フラグに削除された日時を入れて更新することで削除されていることを示す。Revison番号は変わらない。
- 削除レコードを追加するという考え方ではなく、削除フラグに日時を入れることで対応する。その理由は、古いRevisonレコードに削除フラグが立たないと検索対象に含まれてしまって不都合だから。また、削除フラグのみの更新であれば、元の情報が消されることもない。
- 情報の鮮度(強弱)
- 同一KeyのレコードではRevisonの大きいものが最新となるが、同一Revisonで削除フラグが立っているものがある場合には、それが最新となる。
- Rev.3(削除なし)>Rev.2(削除あり)>Rev.2(削除なし)>Rev.1(削除ありなし)
大福帳管理モデル 更新のサンプルとパフォーマンス
以下にサンプルコードを示す。これはカウンタをもつEntityGroupを構成するタイプで、最新レコードに件数をもつタイプではない。
拙作のReflexGaeを利用している。
ReflexGaeの特長は、JDOのEntityをLow Level APIを使ってGET/PUTできるところ。なんのこっちゃ!?と思うかもしれないが、要はJDOがヘタレなのでLow Level APIでラッパーを作った。その際、EntityはJDOと完全に互換性をもたせるようにした。(JDOがダメダメと言い出したのはたぶん私が最初だと思うが、概念というか、Entityの構造まで否定したつもりはなく、実はこれはこれで気に入っていたりする)
ReflexGaeには、KeyUtils、EntityConverter、FieldMapperというものがあり、以下のようなことができる。
1.KeyUtilsを使って、EntityGroupを作成する
2.EntityConverter().convert(RECORD_KIND_CLASS, entity); で、EntityクラスからJDOクラスに変換する
3.fieldMapper.setValue(current, target); で、JDOの@Persistent項目で更新があるものだけをセットする
Entity変換ではReflectionを使っているが高速である。
速度比較
- 登録(登録 + カウンタ更新・・EntityGroup更新)
- JDO : 0.251s
- ReflexGAE : 0.163s
- 更新(1レコード登録 + 1レコード(旧Revision)・・同一Kind更新)
- JDO : 2.790s
- ReflexGAE : 0.250s
検索ではJDOは1万件以上でタイムアウトになるので単純に比較できないが、ReflexGaeは次の通り。
- keyによるget : 0.030s
- query : 0.622s (92300件対象にSort条件をつけて1件取得)
ちなみに、Memcacheへの登録参照はココによれば、0.015s程度とのこと。
GAEのスケーラビリティ、特にTaskQueueについては、いろいろ調査してわかってきたので、このあたりで報告したいと思う。GAE Night#3で話すネタと若干かぶるかもしれないが、全部は時間の関係で話せないと思うので、あらかじめこのBlogに晒しておくことにする。もちろん、被らないネタもある。(今回はさわりだけで、次回以降に詳細を書く。複数回に分けて書くつもり)
GAEのスケーラビリティについて
「リニアにスケールするように作れる」からこそのGoogle App Engineより抜粋
その中でも一番収穫として大きいのは、「Google App Engineを使えば、リニアにスケールするサービスを作ることが可能」だということが実感できたこと。(中略)・・・
ユーザーの数が100万人から1000万人に増えた時には、単にマシンの台数を10倍にすれば良いという話ではなく、それに応じてデータベースを新たにクラスタリングさせたり、スケーラビリティの確保のために新たなデータキャッシュの仕組みを導入したり、ということがどうしても必要になる。その結果、マシンの数が10倍ではなく20倍必要になったり、スケーラビリティのことだけを専任で担当するエンジニアが何人も必要になったりする。
私もGAEがリニアにスケールすることに感動して、Scaleするかどうか、それが問題だとか、いろいろいってきた一人である。しかし、皆さんも経験しているとおり、GAEといえどもリニアにスケールするアプリを作るのは一筋縄にはいかない。単純なアプリでデータ件数も少ないのであれば、AppServerのインスタンスが勝手に増えてスケールしていくのだが、アプリがちょっと複雑になったり、データが多くなってくると、すぐに30秒ルールの壁にぶちあたってスケールしなくなる。スケーラビリティは、リクエストの数というより、特に大量のデータ処理をやろうとしたときに問題となるようである。
並列処理とTaskQueue
30秒ルールがあるからスケールしない理由と考えるのは本末転倒である。そもそも、30秒以内にレスポンスを返せないと使い勝手が悪くなり、ユーザビリティ要件を満たせなくなる。なので、そこはアプリの方でなんとか頑張らんといけないのであるが、GAEのAppServerのCPU処理能力は低いので、なかなか思ったように捌けないのが現実である。
なんとか素早くレスポンスするために、並列処理させるのも一案である。TaskQueueを使えば、大量のデータを分割して複数のマシンで同時に実行できる。簡単にいえば、1台のサーバで10分かかる処理は、20台のサーバであれば30秒で処理できるようになる。無尽蔵にあるサーバに対して、複数のTaskで並列処理させる。それがクラウドの醍醐味であり、本当の意味でリニアにスケールする仕組みであるといえる。しかも、20台を30秒使うのは、1台を10分使うのと同じCPU利用時間なので、同じ利用料で済む。これが本当ならば、まるで夢みたいな話である。
だが残念なことに、現在のところはまだ夢のようである。Googleは、無尽蔵にあるサーバを無尽蔵には使わせてはくれない。私たちの検証の結果では、TaskQueueの並行実行には限界があり、10/sという設定をしているにも関わらず、インスタンスの起動は同時に4つまでしか行われなかった。MLにも同じようなことが報告されている。
Hi there,
Last night I experimented with task queues to see what level of
concurrency I could achieve when running on the live environment.
Summary of the test app:
- Bulk load 30,000 entities of a given type (3 properties / entity
object).
- Command line job I ran from my PC that hit an URL to queue the
entries
- This program was multi-threaded so I could simulate a bit of
load (10 concurrent threads)
- Queueing URL created a task queue entry within the same app
- 2nd URL handled the task queue request and stored entity to the
Datastore
I watched the task queue dashboard for a few minutes and observed a
few things:
- Enqueue rate quickly outpaced dequeue rate
- I was enqueing at about 12 requests / second, but dequeuing at
4 requests / second
- GAE did not appear to increase the dequeue rate over time in
response to my queue depth
Result: It took a very long time to dequeue 30,000 tasks (over 2
hours). It seemed that GAE was running one instance of my app.
Expected: Much higher throughput.
Is this expected behavior? It seems that given the 30 second request
limit that task queues are an important way to increase throughput
(ala MapReduce). But the "swarm" of app instances never seemed to
arrive.
thanks
-- James
aha! I missed that. I wonder if "task invocations/second" means
"dequeues/second".
If it means dequeues/second then in theory you could write a request
handler that burns through a queue of work items in the datastore, re-
queueing itself and exiting after 25 seconds and achieve 250 CPU
seconds/second of concurrency.
Is that crazy talk?
I hope these limits go up when Tasks Queues exits beta. Google is
selling us computer time but is setting some fairly low limits on what
we're allowed to buy. 10 cores of 1.2ghz CPU time is roughly
equivalent to a modern 4 core desktop machine right?
そりゃ、1つの検索リクエストに20台のサーバを使われたら、Googleといえども、たまったもんじゃないのかもしれない。いずれにしても、TaskQueueはまだLabs releaseであり、今は実験中であって、使われ方とサーバへのインパクトを見ながら徐々に増やしていくのだろう。実際にTask Queue Quota Increasesにもあるように、QuotaやTotal execution rateも上がってきているし、今後はもっと改善されていくと思われる。
<続く>
<追記>
・ 軽いWorkerタスクを別途用意して連続して負荷をかけることでVMは16程度起動することがわかっている。今度はServletContext+UUIDで負荷分散状況を調べてみた
・ WdWeaverさんの実験 スケールアウトの真実
カウンタとレコードのシーケンス番号
レコードにシーケンス番号(連番)をつけると、全体の件数を取得できたり、Pagingできたりするので、いろいろと好都合である。Pagingだけであれば、わざわざシーケンス番号を付ける必要はないが、大量のレコードを分割してTaskQueueで並列処理させたい場合には、シーケンス番号で範囲指定を行うとよい。(全体の件数はStatics APIでも取得できる)
シーケンス番号を付けるには、カウンタを管理するEntityを用意して、挿入のたびにインクリメントする方法が一般的だと思うが、これだと前記事で述べたように、カウンタのEntityとデータのEntityをEntityGroupとして括ってしまうことが大きなボトルネックとなってしまう。しかし、トランザクションで括らないと挿入に失敗することがあるため歯抜けのシーケンス番号となってしまう。
そこで、カウンタのEntityを使わないで、うまくシーケンス番号をつける方法がないものか考えてみた。
EntityGroupを使わないでシーケンス番号をつける方法
すぐに思いつくのが、既存データのシーケンス番号の最大値を取得して、それに+1したものを、新規に追加するレコード番号としてセットする方法。
まず、シーケンス番号をidとすると、
query.addSort("id", Query.SortDirection.DESCENDING);
とし、最初の1件を取得することでレコードの最大値を取得する。(これにかかる実行時間は10万件レコードでも約0.6秒と高速である。)そして、この値に+1したものを新規レコードのidとしてセットする。
これは一見うまくいくように思えるが、取得して更新する間に他の人が追加してしまう場合があるので意味がない。トランザクションで括ればいいと思うかもしれないが、やっかいなことに、queryはトランザクションに参加することができないので、一旦、最大値をqueryで取得しておいて、ユニーク制限を行ったPUTを実行することになる。これは、少々冗長かもしれないが、EntityGroupを使う場合に比べ、排他対象がKindからレコードに狭まるので、その分並行実行可能になって高速になると思われる。 ユニーク制限を行ったPUTについては、詳しくは、ひがさんのBlog、App Engineのユニーク制限を正しく理解しよう)を参照してもらいたい。
レコード挿入時
1.queryでシーケンス番号idの最大値を得る
2.+1したidをセットした新規レコードを作成してputUniqueValue()する
3.エラーで返ってきた場合、さらにidを+1してputUniqueValue()を再実行
putUniqueValue(String uniqueIndexName, String value)
1.valueを元にKeyを生成
2.トランザクション開始
3.生成したKeyでGET。既に存在していればエラーで返す。
4.もしなかったらPUTしてコミット
これは、どんなにデータが増えても、Query(0.62s)とKeyによるGET(0.03s)の2回の検索および、PUT(0.25s)でシーケンス番号を作成できる。しかし、リクエストが増えてしまうと、コンテンションが多発してリトライ回数が増えるため、もう少し時間はかかる。それは、QueryからPUTまでの0.62s+0.03s+0.25s)の間にどれだけのリクエストが入ってくるかによる。リトライは2回目以降はQueryはしないので、GET(0.03s)を繰り返すことになる。また、GETで成功してもPUTまでの間に他によって更新されていると、ConcurrentModificationExceptionが発生してリトライとなるが、よほどのリクエストがこない限り大丈夫だと思う。たぶん。ちなみに、件数が増えてもQueryが速いのはPropertyIndexのおかげである。
さらなる応用、最新レコードに件数を格納する
履歴をレコードとして持つ場合、idの最大値やDatastore statisticsのcountだと履歴分も全て件数に含まれてしまうので注意が必要である。また論理削除する場合も同様に削除データが件数に含まれる。履歴を持つ、または論理削除する場合では、条件を指定してKeyの個数を検索する方法もアリだが、10万件で約17秒かかるので、十数万件になると30秒ルール(あるいはTaskQueueの10秒ルール)にひっかかって使えなくなってしまうだろう。
これには、以下のように最新のレコードに件数を格納することで、対応することができる。(もちろん、カウンタEntityを別途用意してもよい)
レコード挿入時に最新の件数を格納する
1.queryでシーケンス番号idの最大値を得る
2.+1したidをセットした新規レコードを作成する。その際、新規レコードのcountプロパティの値を更新する。(追加であれば+1、削除であれば-1、更新であれば何もしない)
3.putUniqueValue()する
4.エラーで返ってきた場合、queryを再実行してidやcountを更新してputUniqueValue()を再実行
ただし、これをやるには、レコードをRevision番号で管理するという前提で考える必要があり、更新において新しいRevision番号でレコードを追加する必要がある。
詳しくは、疎結合とバージョニングについてを参照のこと。


























{kind=link}